PTT Point版 爬蟲 擷取長榮哩程售價資訊 ptt-web-crawler
前陣子都有在賣EVA BR的哩程
兩年多來從0.5一直跌到0.43
以前都用AE簽帳卡現在一堆國泰長榮聯名卡讓積分越來越沒價值
想說利用Python來將近年來所有資料抓來分析看看是否如此
不過要有大量的數據才能作分析
PTT Point版上有很多販售哩程資訊
第一步驟就需要爬蟲把所有資料抓下來處理
https://github.com/jwlin/ptt-web-crawler
github已經有人寫好相關套件可以拿來使用
看起來評價應該不錯也不少人在使用

輸出是JSON格式應該很好後續處理
他可以直接指定要抓哪個index資料
一個inxdex有20篇文章
我想抓歷史資料就需要抓 index 1~1466

 比較特別的是最新這頁就沒有index可以抓取
比較特別的是最新這頁就沒有index可以抓取

先去git clone把整包抓下來
 https://github.com/jwlin/ptt-web-crawler.git
https://github.com/jwlin/ptt-web-crawler.git
 抓下來後裡面有個資料夾
抓下來後裡面有個資料夾
直接在裡面執行python檔就可以抓取資料


不過如果一次把所有資料都抓下來的話
檔案應該會太大
而且又怕被鎖IP
所以大概寫隻小程式來抓
以10個index為一個單位
然後抓完再稍微delay一下避免被鎖定
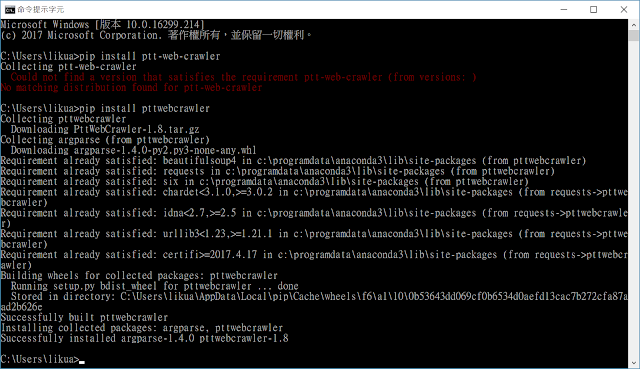
本來以為這個套件沒再pip套件管理程式內要手動安裝
後來發現其實只是名稱不對
 不過後來發現這個版本趴起來有點怪怪的
不過後來發現這個版本趴起來有點怪怪的
應該不是我程式寫的問題吧?
 仔細對一下版本
仔細對一下版本
pip install裡面是1.8版
https://pypi.python.org/pypi/PttWebCrawler
仔細去看一下github裡面內容
https://github.com/david30907d/ptt-web-crawler
看起來還是跟之前clone下來版本更新時間差了幾個月
https://github.com/jwlin/ptt-web-crawler
最後還是決定clone下來自己裝最新版好了
因為試著抓起來比較沒問題
安裝方式:
用系統管理員開cmd line

不確定為什麼import進來都失敗
不知道哪邊設定有問題
最後把所有資料全抓完大概花了七個多小時
大概抓了三萬篇文章下來可以分析

兩年多來從0.5一直跌到0.43
以前都用AE簽帳卡現在一堆國泰長榮聯名卡讓積分越來越沒價值
想說利用Python來將近年來所有資料抓來分析看看是否如此
不過要有大量的數據才能作分析
PTT Point版上有很多販售哩程資訊
第一步驟就需要爬蟲把所有資料抓下來處理
https://github.com/jwlin/ptt-web-crawler
github已經有人寫好相關套件可以拿來使用
看起來評價應該不錯也不少人在使用

輸出是JSON格式應該很好後續處理
他可以直接指定要抓哪個index資料
一個inxdex有20篇文章
我想抓歷史資料就需要抓 index 1~1466



先去git clone把整包抓下來



直接在裡面執行python檔就可以抓取資料
python crawler.py -b points -i 1 2
這樣就可以將index 1 ~2文章趴出

檔名為points-1-2.json
最後檔案為json format所以相當好整理
不過如果一次把所有資料都抓下來的話
檔案應該會太大
而且又怕被鎖IP
所以大概寫隻小程式來抓
以10個index為一個單位
然後抓完再稍微delay一下避免被鎖定
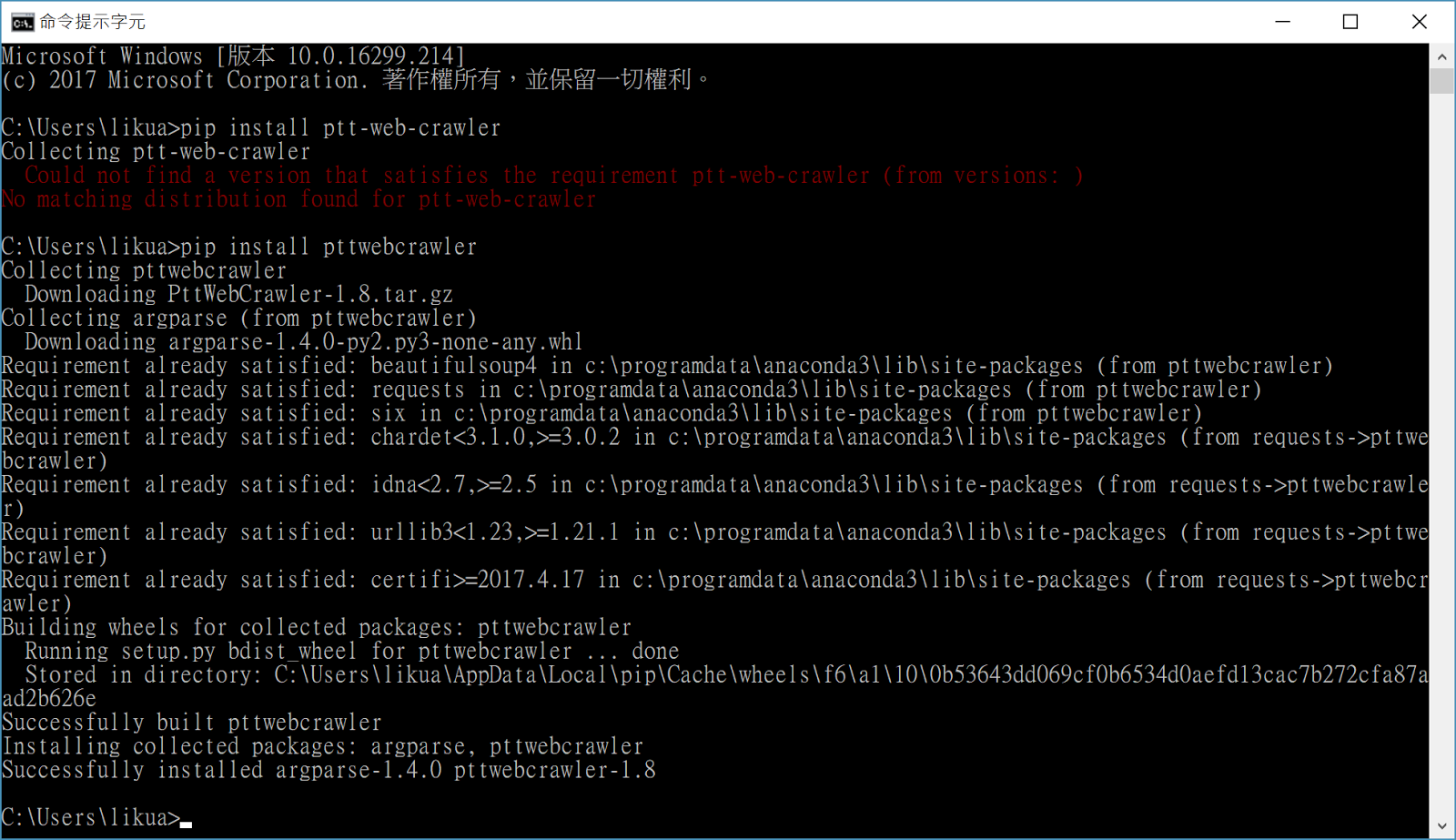
本來以為這個套件沒再pip套件管理程式內要手動安裝
後來發現其實只是名稱不對
pip install pttwebcrawler
應該不是我程式寫的問題吧?

pip install裡面是1.8版
https://pypi.python.org/pypi/PttWebCrawler
仔細去看一下github裡面內容
https://github.com/david30907d/ptt-web-crawler
看起來還是跟之前clone下來版本更新時間差了幾個月
https://github.com/jwlin/ptt-web-crawler
最後還是決定clone下來自己裝最新版好了
因為試著抓起來比較沒問題
安裝方式:
用系統管理員開cmd line
python setup.py install

import os, time
def FirstTimeGetAllData(Board, StartIndex, EndIndex, NumPerTime, DelaySeconds):
startTime = time.time()
for StartIdx in range(StartIndex, (EndIndex+1), (NumPerTime+1)):
if ((StartIdx + NumPerTime) > EndIndex):
NumPerTime = EndIndex - StartIdx
crawlercmdlin = "PttWebCrawler -b " + Board + " -i " + str(StartIdx) + " " + str(StartIdx+NumPerTime)
print(crawlercmdlin)
os.system(crawlercmdlin)
print("Delay:" + str(DelaySeconds) + "\n")
time.sleep(DelaySeconds)
endTime = time.time()
elapsedTime = endTime - startTime
print("Time taken: " + str(elapsedTime) + "seconds.")
def main():
FirstTimeGetAllData('points', 1, 1466, 10, 5)
if __name__ == '__main__':
main()
最後用cmd line方式把它全部dump下來不確定為什麼import進來都失敗
不知道哪邊設定有問題
最後把所有資料全抓完大概花了七個多小時
大概抓了三萬篇文章下來可以分析


留言
張貼留言